实现前提:数据库实现主从复制,并且已经开启并行复制,并行复制实现可以参考这篇文章:
参考文章:[MySQL高级](七) MySQL主从复制及读写分离实战睁眼看世界-CSDN博客mysql主从复制
安装
下载Mycat-server-1.6.7.4
本次安装的版本为Mycat-server-1.6.7.4,如果想要选择其他版本可以到该网站进行查找发布文件(mycat.org.cn)
cd /opt/
wget http://dl.mycat.org.cn/1.6.7.4/Mycat-server-1.6.7.4-release/Mycat-server-1.6.7.4-release-20200105164103-linux.tar.gz
解压Mycat
该中间件由于是已经编译完成的版本,所以解压完成之后即可使用
tar zxvf Mycat-server-1.6.7.4-release-20200105164103-linux.tar.gz
解压完成后,目录如下:
目录 说明 bin mycat命令,启动、重启、停止等 catlet catlet为Mycat的一个扩展功能 conf Mycat 配置信息,重点关注 lib Mycat引用的jar包,Mycat是java开发的 logs 日志文件,包括Mycat启动的日志和运行的日志。
运行Mycat
$ cd /opt/mycat/bin
./mycat start # 启动
./mycat stop # 停止
./mycat console # 前台运行
./mycat restart # 重启服务
./mycat pause # 暂停
./mycat status # 查看启动状态
查看Mycat的运行状态
./mycat status

- wrapper.log 为程序启动的日志,启动时的问题看这个
- mycat.log 为脚本执行时的日志,SQL脚本执行报错后的具体错误内容,查看这个文件。mycat.log是最新的错误日志,历史日志会根据时间生成目录保存。
注意:运行之前需要保证服务器有jdk的环境,否则会报如下错误:
首次启动失败wrapper.log的内容:
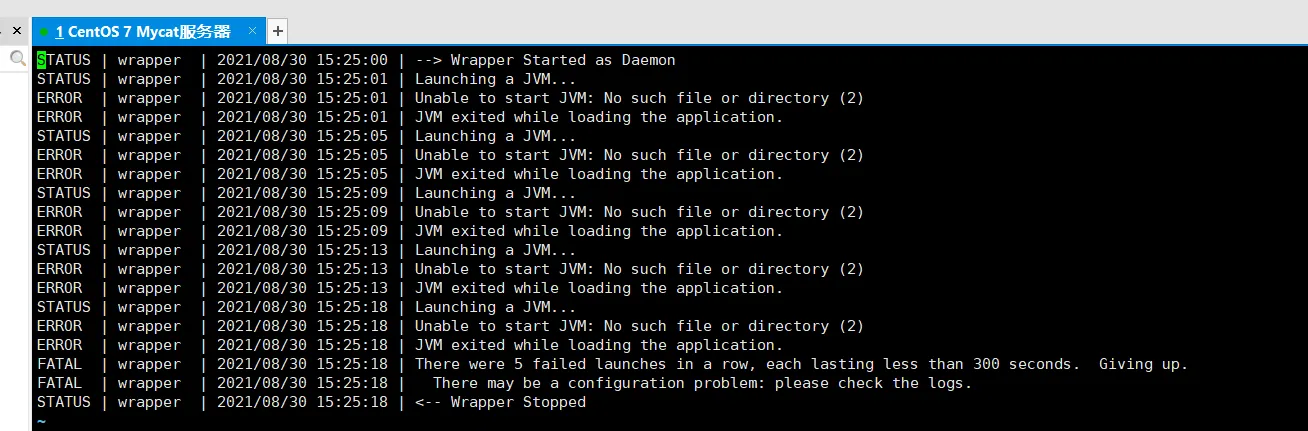
安装jdk1.8
查看可安装版本
yum search java|grep jdk
安装jdk1.8
yum install java-1.8.0-openjdk-src.x86_64
重新启动服务看到服务已经启动:

配置Mycat
从库添加测试用户
在从库中添加测试用户test,并为其赋予查询权限
添加test用户:
CREATE USER 'test'@'%' IDENTIFIED BY '123456';
给test用户授权:
GRANT SELECT ON mycatdb.mycattable TO 'test'@'%';
或者添加用户、授权一步到位:
GRANT Select ON *.* TO 'test'@'%' IDENTIFIED BY "123456"
开放8066端口
#开放8066端口
firewall-cmd --zone=public --add-port=8066/tcp --permanent
#重启防火墙使配置生效
firewall-cmd --reload
在此仅配置简单的读写分离。
为了让读者能够明白以下配置步骤,值得说明的是我们的物理数据库(即实实在在的数据库)名称为mycatdb,物理表名为mycattable
server.xml的配置
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">TESTDB</property>
<property name="readOnly">false</property>
<property name="defaultSchema">TESTDB</property>
<!--No MyCAT Database selected 错误前会尝试使用该schema作为schema,不设置则为null,报错 -->
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
该用户配置在配置文件比较靠下的位置,除了root用户默认还有一个user用户。
参数说明:
参数 说明 user 用户配置节点 –name 用户登录名,即连接mycat服务的用户名 –password 用户登录密码,即连接mycat服务的用户密码 –schema 数据库名,这里会和schema.xml中的配置关联,多个用逗号分开
例如需要这个用户需要管理两个数据库db1,db2,则配置db1,db2–privilege 配置用户针对表的增删查改的权限,具体配置可参照官方文档 这里我配置一个
root用户,密码为123456,逻辑数据库的名称为默认的TESTDB,实际配置中可以改,但是要和schema.xml中的配置一一对应。其中逻辑数据库是指会在连接Mycat服务时显示的数据库,并不是物理数据库。
schema.xml的配置
schema.xml文件是主要配置文件,其中各种参数读者可在后续参考官方文档进行了解,在这我只展示需要进行改动的点。
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"/>
<dataNode name="dn1" dataHost="think" database="mycatdb" />
<dataHost name="think" maxCon="1000" minCon="10" balance="3"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user();</heartbeat>
<writeHost host="hostM1" url="192.168.20.6:3306" user="root" password="root">
<readHost host="hostS1" url="192.168.20.11:3306" user="test" password="123456" />
</writeHost>
</dataHost>
</mycat:schema>
注意:读库中的
test是上面所配置的用户,仅具有查询权限。readHost节点为读节点,位于写节点中,配置显而易见的。在这个配置中没有table节点。与默认的配置文件不同还有schema节点中的dataNode参数,默认配置文件中的参数为randomDataNode读者可根据具体需求了解该参数的具体含义再进行配置,现阶段按照上面的配置是可行的。各个节点参数说明:
schema:
参数 说明 schema 数据库设置,此数据库为逻辑数据库,name与server.xml中schema对应 –checkSQLschema 数据库前缀相关设置,建议看文档,这里暂时设为false –sqlMaxLimit select时默认的limit,避免查询全表 –dataNode 分片信息,也就是分库相关配置,与下面的dataNode所配置的name对应 dataNode:
参数 说明 dataNode 分片信息,也就是分库相关配置 –name 节点名,与schema中dataNode对应,如果有table节点配置则与table中的dataNode对应 –datahost 物理数据库名,与datahost中name对应 –database 物理数据库中的数据库名 dataHost:
参数 说明 dataHost 物理数据库,真正存储数据的数据库 –name 物理数据库名,与dataNode中dataHost对应 –balance 负载均衡的方式 –writeType 写入方式 –dbType 数据库类型 –hearbeat 心跳监测语句,注意语句后面后结束分号一定要加
测试连接
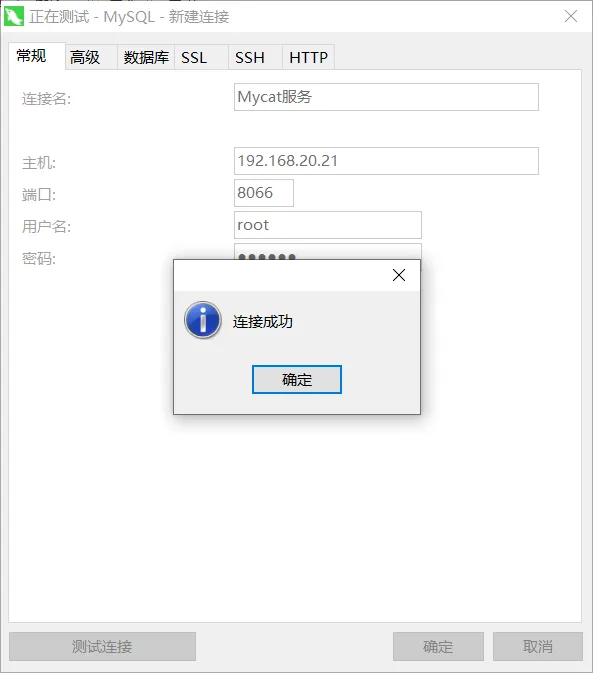
连接Mycat
使用Navicat进行连接:
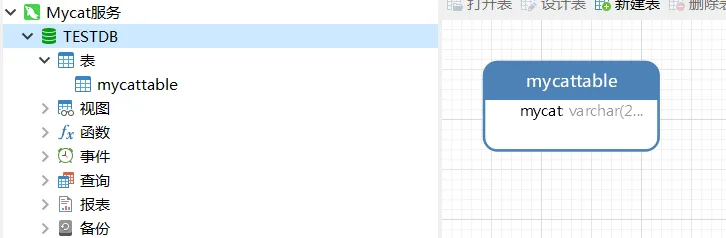
展开TESTDB可查看数据库详情:
测试读写分离
- 在通过Mycat插入一条数据
insert mycattable (mycat) values ('hello');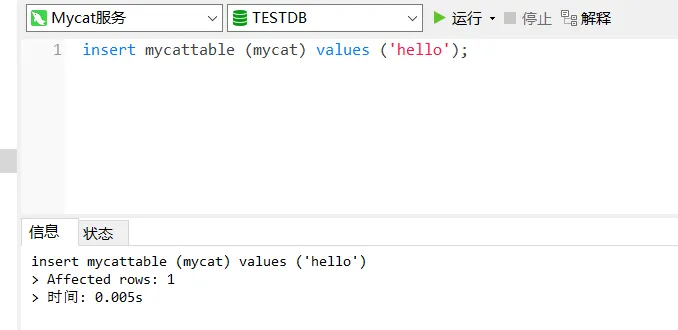
- 查看主从库中的数据主库:
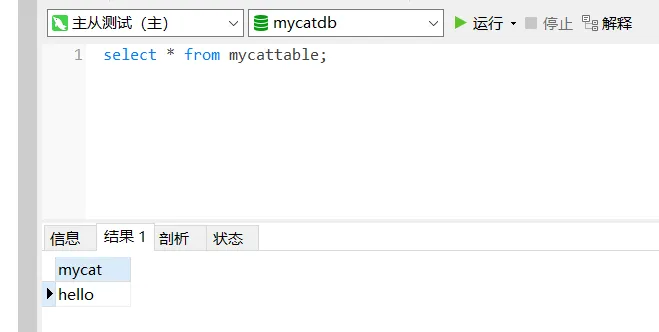
从库:
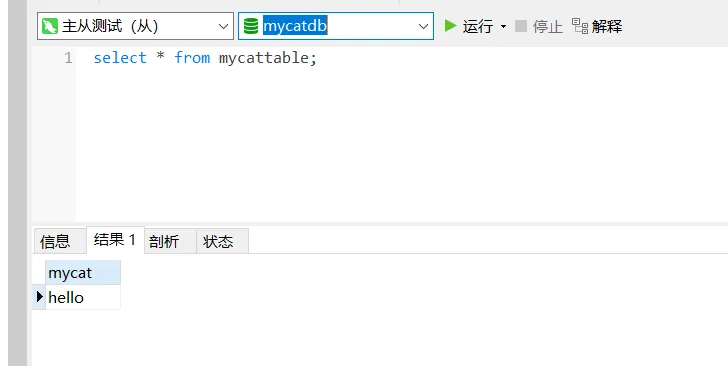
- 修改从库中
mycat字段的值为“world”update mycattable set mycat = 'world';
- 查看主库的
mycat的值,理应还是“hello”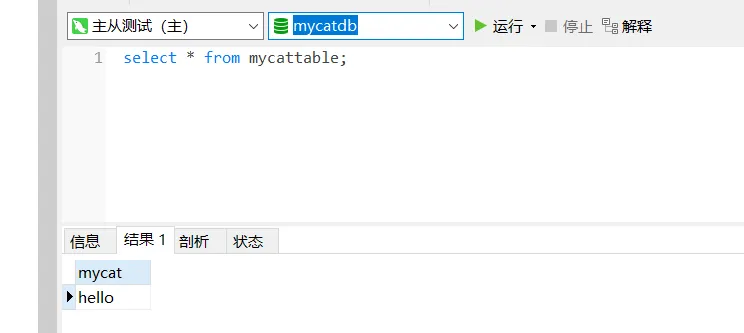
- 最后如果通过
Mycat服务来查看mycat字段的值,结果为“world”则表示测试成功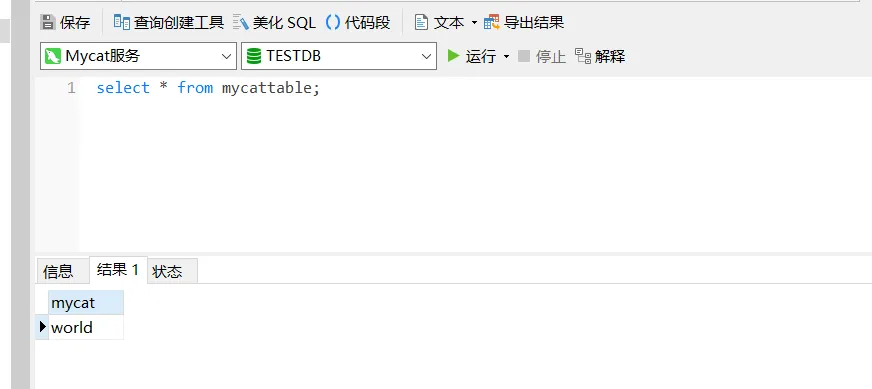
功能实现成功!!!
总结
本次是在MySQL主从复制,并且开启从库并行复制的前提下进行的读写分离,该技术或许还存在有一定不足,例如:在高并发环境下是否能够保证数据的同步以及事务的一致性。但作为入门数据库读写分离的技术而言,这一套方案还是非常值得尝试的。如果文章中出现有错误还望各位读者指出,如果有更好的解决方案也可以相互交流。
