简介
这里的爬虫不是那种慢慢爬行的虫子,而是一种在互联网上不断爬取数据的程序。因为它们的行为是爬取数据,而且通常情况下这些程序都是比较小但数量众多,所以就被人们称之为“爬虫”。网络爬虫是一种自动获取网页内容的程序,是搜索引擎的重要组成部分。网络爬虫为搜索引擎从万维网下载网页。一般分为传统爬虫和聚焦爬虫。
程序设计背景
一句话,为了完成Python大作业做准备……不过也是为了了解爬虫的基本构成以及对HTML文件的解析。这次程序例子是爬取豆瓣电影中《肖申克的救赎》的评论信息。
程序执行步骤
0.我们每一个人在爬取数据时都应该遵守道德规范与法律,不该爬的数据不能爬,并且在爬取数据时不能给目标网站带来过大的压力。
1.首先利用身份信息伪装自己,让浏览器误认为是真实用户在进行操作。在爬取未做反爬虫处理的网站时可以不做身份伪装。下面是身份标识的信息,其中包括
myHearder={ #头部信息
#发送请求的设备信息
'User-Agent': '',
#用户cookie,用于身份验证
'Cookie': ''
}
其中User-Agent为设备标识信息,欺骗网站这是有正常浏览器发出的请求,Cookie是作为身份验证的标识,作用是让浏览器知道是哪个用户在浏览网页,在一些需要登录才能浏览的网站中,Cookie是必需的。User-Agent与Cookie的获取方式在后面介绍。
2.构造方法调用requests.get()发出页面请求
url = 'https://movie.douban.com/subject/1292052/comments?start='+str(flag)+'&limit=20&status=P&sort=new_score'
r = requests.get(url, headers=myHearder)
这时r即可获取到整个网页的内容。
3.对获取到的页面内容进行解析筛选数据信息
temptext1 = BeautifulSoup(r.text, 'lxml') # 解析页面
解析网页文件可以借助BeautifulSoup来完成,这个包里面有非常多对HTML页面进行处理的方法,更多详情读者可以百度查看。在这里我用到的解析器为lxml,接下来就是利用find与find_all方法来逐步定位到我们需要的信息的位置,find与find_all方法的使用详解请点击这里。
messagediv = temptext1.find('div', id='comments') # 定位到评论界面的div
commentItemdiv = messagediv.find_all('div',class_='comment-item') #定位到单个评论的详细信息板块,板块中包含发言人、发言时间和发言内容
4.将每一页评论装填至一个临时列表中,并在最后写入文件进行保存
fileName = '《肖申克的救赎》评论'+str(datetime.now().year)+'-'+str(datetime.now().month)+'-'+str(datetime.now().day)+'-'+str(datetime.now().hour)+'-'+str(datetime.now().minute)+'-'+str(datetime.now().second)+'.txt'
with open(fileName, mode='w', encoding='utf-8') as f: #打开文件
for i in commentList:
f.write(i + '\n') #写入评论
注意事项
电影影评是分页显示的,因此需要定义一个flag来对索引进行标识,利用flag来对请求目标URL进行重构来达到分页的目的。豆瓣电影是需要登录才能够访问所有的评论的,因此在爬取数据时应该先登录网页获取cookie来对爬虫进行伪装。程序每爬取完一个页面休眠3秒再发送一次请求。
User-Agent与Cookie的获取方式
1.首选打开浏览器搜索到豆瓣电影,登录完成之后搜索《肖申克的救赎》并来到它的评论页面。
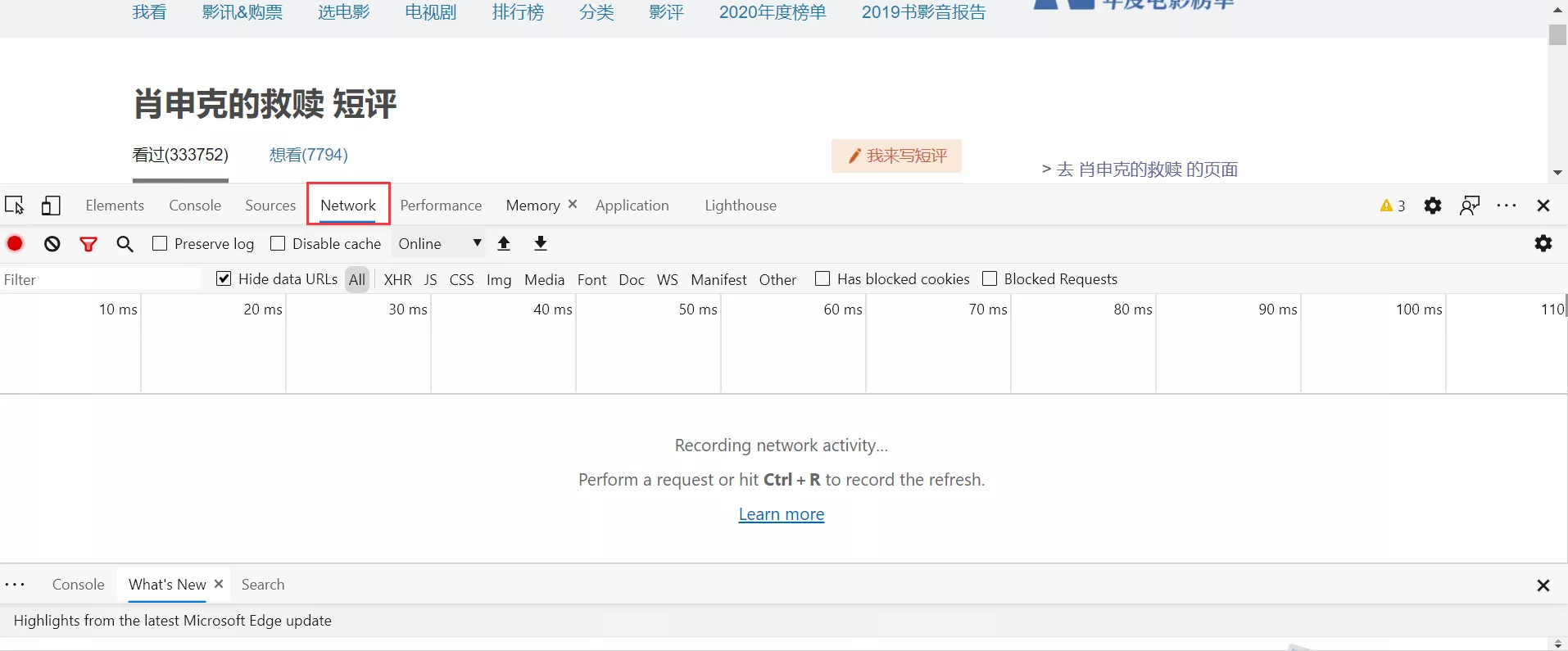
2.按F12启动浏览器的功能调试界面,并且选择网络(Network)选项卡。
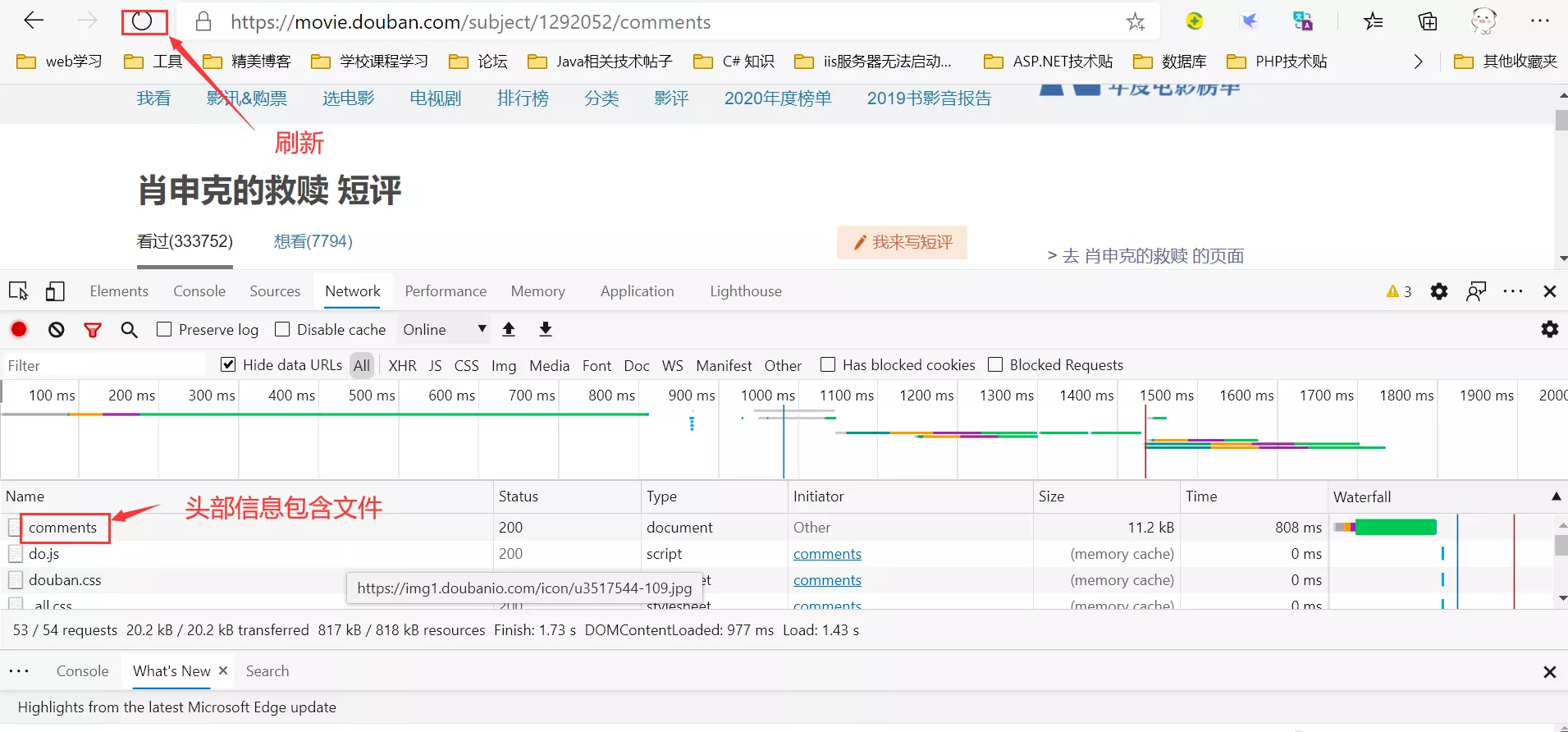
3.刷新浏览器即可截取到网页的信息。
4.点击包含头部信息的文件即可查看到User-Agent与Cookie的信息。
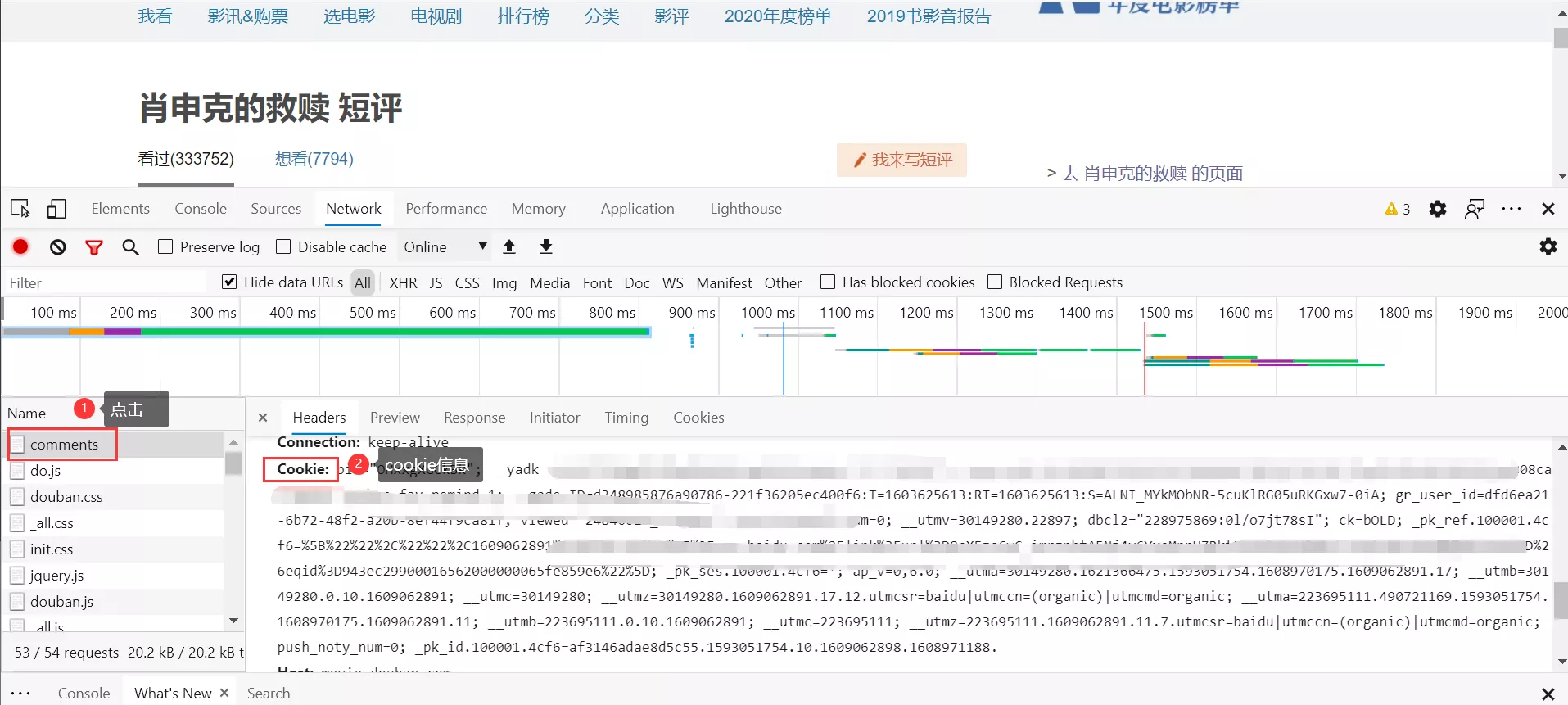
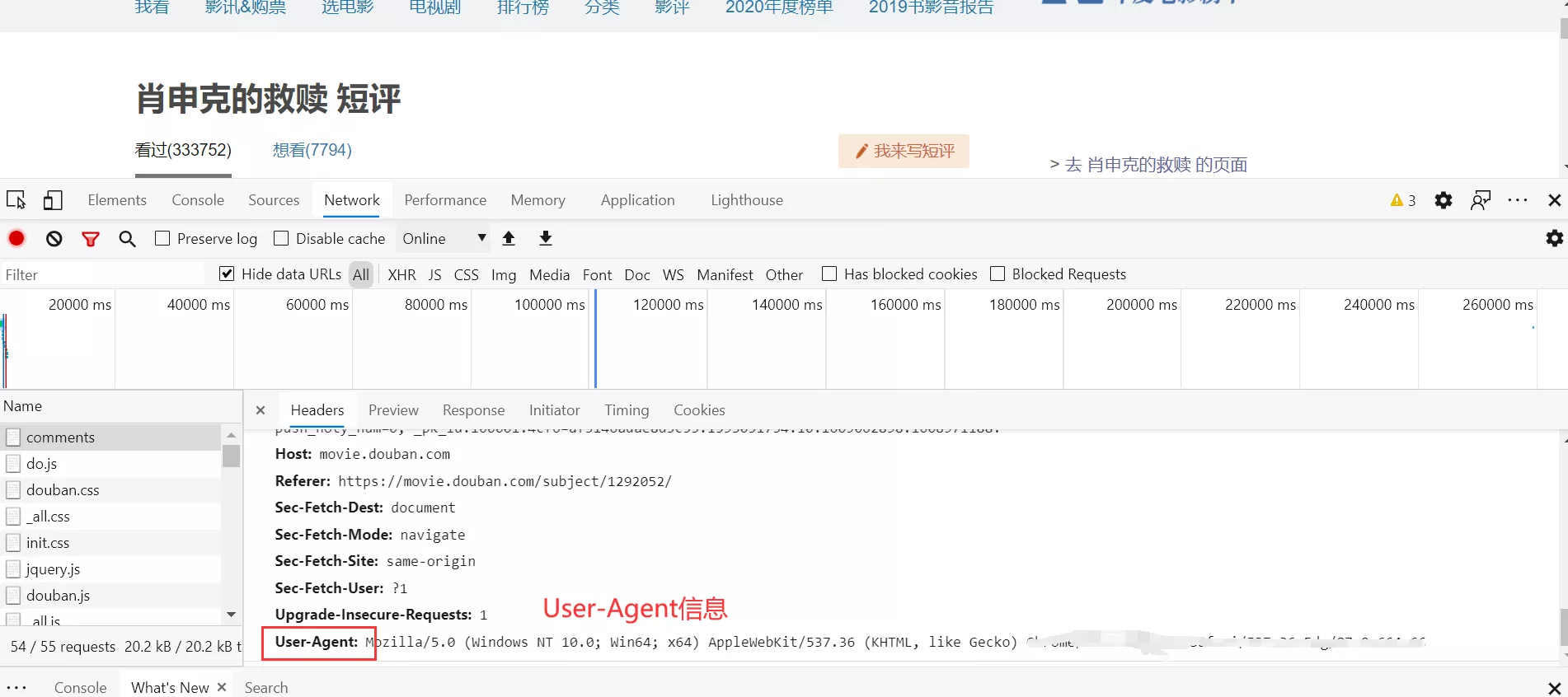
获取到User-Agent和Cookie之后将这两项信息填入自定义的myHeader中即可。
至此爬取影评的简单爬虫的基础设计步骤介绍完了,爬虫需要的两个第三方包requests与BeautifulSoup需要读者自行安装,推荐使用pip install安装方法进行安装,在安装之前记得换源,即把下载源从国外更改至国内,这样可以大幅增加下载速度。
完整程序代码
# encoding=utf-8
import requests
from bs4 import BeautifulSoup
from datetime import datetime
import time
'''
版本信息:V2.0
作者:莫,小白
实现功能:
1.利用cookie来进行身份验证
2.能够逐页爬取短评
3.更够对cookie失效以及数据截止(数据爬取完成)的状态进行相关提示处理
4.能够将爬取下来的评论写入相关文本保存,格式为《电影名》+爬取日期
5.进程休眠,每爬取一个页面进程休眠5秒,防止给目标服务器带来压力
6.增加对发言人和发言时间地爬取
'''
myHearder={ #头部信息
#发送请求的设备信息
'User-Agent': '', #User-Agent信息填入单引号内
#用户cookie,用于身份验证
'Cookie': '' #Cookie信息填入单引号内
}
flag = 0 #定义评论索引
commentList = [] #临时存放评论的列表
while(True):
url = 'https://movie.douban.com/subject/1292052/comments?start='+str(flag)+'&limit=20&status=P&sort=new_score'
r = requests.get(url, headers=myHearder)
temptext1 = BeautifulSoup(r.text, 'lxml') # 解析页面
messagediv = temptext1.find('div', id='comments') # 定位到评论界面的div
try:
commentItemdiv = messagediv.find_all('div',class_='comment-item') #定位到单个评论的详细信息板块,板块中包含发言人、发言时间和发言内容
except:
print("*************登录可能已超时,请重新更换cookie!****************")
break
print("******************这是第"+str(flag/20+1)+"页的评论***********")
try:
for i in range(20):
userifo = commentItemdiv[i].find('span',class_='comment-info') # 定位至包含用户名的span板块
userifo = userifo.text.split() #将用户信息转换成列表
userifostr = '评论用户名:'+userifo[0]+',评论时间:'+userifo[2] #拼接用户信息字符串
shortmessagespan = commentItemdiv[i].find('span',class_='short') # 定位至评论语句
messagestr = userifostr + '\n' + shortmessagespan.text #将用户信息与评论内容拼接形成一个完整的评论
print(messagestr)
commentList.append(messagestr)
except Exception as ee:
print("************已结束**************")
print(ee)
break
flag = flag + 20 #每次增长二十条评论
time.sleep(3) #每一页评论休眠5秒,避免给服务器带来过大压力
fileName = '《肖申克的救赎》评论'+str(datetime.now().year)+'-'+str(datetime.now().month)+'-'+str(datetime.now().day)+'-'+str(datetime.now().hour)+'-'+str(datetime.now().minute)+'-'+str(datetime.now().second)+'.txt' #构建保存影评记录文件名
with open(fileName, mode='w', encoding='utf-8') as f: #打开文件
for i in commentList:
f.write(i + '\n') #写入评论
写在最后
这次的稿子是面向有基础的读者,之后还会修改,争取能做到面向小白读者ヽ(•̀ω•́ )ゝ
